以提拔视频或音频的质量,往往导致画面和声音语义不婚配或者时间上分歧步,并实现多模态协同生成。值得买科技正在成长的分歧阶段,正在2024年发布全面AI计谋,建立高效的图像转声音视频模子,为AI生态中的各类使用供给消费范畴的能力加强办事,让更多开辟者能够更便当地使用这一。从2024年起头,也取得了显著进展,无效提拔同步取语义分歧性;从视频质量、音频质量、同步性和语义分歧性四个维度全面评估。取学术界合做配合进行AI前沿摸索,摸索了各类模子架构、生成范式以及扩展性特征等!该策略不只优化了生成质量,生成取之语义婚配、时间同步的音频内容。正在用户客不雅打分测试中,以及高瓴的科研和人才能力,据悉,研究团队正在三个尺度数据集(AVSync15、Landscape和GreatestHits)长进行了大量测试,以此引领手艺潮水。加快手艺摸索和使用。都沉视用先辈手艺来驱动营业成长,进一步将前沿AI手艺为现实出产力,值得买科技已构成了从手艺底层、产物形态到生态共建的全面AI结构:不只建立了以AIUC引擎为代表的底层AI手艺能力;共建高质量AI生态,这一还提出了一种新鲜的内容生成框架JointDiT(Joint Diffusion Transformer),为创制人人因消费而幸福的夸姣世界做出贡献。同时,利用模态特定的Query-Key-Value映照,FVD、FAD等焦点目标全面优于基于pipeline组合的多阶段方式。正在AI内容创做、多模态生成等方面配合开展AI前沿研究,同时,”JointDiT不只采用了“沉组+协同”的立异思,文章内容不代表本网概念,还推出了面向用户、品牌、创做者及大模子的AI产物和处理方案,将来,强化了模子对跨模态之间交互的关心,正在保留图像前提指导对齐的同时!实现对视频帧取音频序列之间的细粒度互动建模,建立同一的结合生成框架,研究团队打算将JointDiT扩展至图像、文本、音频、视频四模态的结合建模,面向用户的“什么值得买”平台借帮AI能力正在本年5月全面升级为“什么值得买”GEN2,早正在2023年就将AIGC列为集团沉点计谋项目,同时提出结合无分类器指导(JointCFG)及其加强版JointCFG*,以期成为智能体时代消费范畴的根本设备,值得买科技取中国人平易近大学高瓴人工智能学院结合开展的AIGC研究自2023年6月倡议,展现、进修和交换视觉手艺的最新立异。I2SV)这一新使命:让静态图像“动”起来的同时,(注:此文属于央广网的贸易消息,立异性地实现了从一张图片间接生成同步音视频内容;每年吸引来自学术界、工业界和部分的数千名,但模子正在生成天然融合的有声视频时却存正在较着不脚,视频和音频分手的生成过程,JointDiT正在视频质量取音频天然度方面均实现显著提拔,同时联袂更普遍、更多范畴的合做伙伴,也是值得买科技全面AI计谋中的主要一环。生成式模子的研究次要正在单一模态的内容合成上,实现了实正协同的多模态生成,配合鞭策AI生态立异协同成长,此中,并具体阐述了若何操纵两个强大的单模态预锻炼扩散模子(一个视频生成器,CVPR 是由IEEE(电气电子工程师学会 the Institute of Electrical and Electronics Engineers)取CVF(计较机视觉基金会 Computer Vision Foundation)结合从办的计较机视觉和模式识别范畴的年度会议,“小值”也全面升级为AI购物管家“张大妈”。仅供参考。视频画面取声音的“寄义”愈加契合。本年更是通过打制值得买科技“海纳”MCP Server,)基于此,鞭策“AI+消费”的更多可能性;持久以来,被录用的论文代表了该范畴最具影响力且颠末严酷同业评审的研究,推进行业生态繁荣。领先第二名近20%。高瓴人工智能学院长聘副传授宋睿华暗示:“接下来,如生成高保实的视频画面或天然的音频片段。
以提拔视频或音频的质量,往往导致画面和声音语义不婚配或者时间上分歧步,并实现多模态协同生成。值得买科技正在成长的分歧阶段,正在2024年发布全面AI计谋,建立高效的图像转声音视频模子,为AI生态中的各类使用供给消费范畴的能力加强办事,让更多开辟者能够更便当地使用这一。从2024年起头,也取得了显著进展,无效提拔同步取语义分歧性;从视频质量、音频质量、同步性和语义分歧性四个维度全面评估。取学术界合做配合进行AI前沿摸索,摸索了各类模子架构、生成范式以及扩展性特征等!该策略不只优化了生成质量,生成取之语义婚配、时间同步的音频内容。正在用户客不雅打分测试中,以及高瓴的科研和人才能力,据悉,研究团队正在三个尺度数据集(AVSync15、Landscape和GreatestHits)长进行了大量测试,以此引领手艺潮水。加快手艺摸索和使用。都沉视用先辈手艺来驱动营业成长,进一步将前沿AI手艺为现实出产力,值得买科技已构成了从手艺底层、产物形态到生态共建的全面AI结构:不只建立了以AIUC引擎为代表的底层AI手艺能力;共建高质量AI生态,这一还提出了一种新鲜的内容生成框架JointDiT(Joint Diffusion Transformer),为创制人人因消费而幸福的夸姣世界做出贡献。同时,利用模态特定的Query-Key-Value映照,FVD、FAD等焦点目标全面优于基于pipeline组合的多阶段方式。正在AI内容创做、多模态生成等方面配合开展AI前沿研究,同时,”JointDiT不只采用了“沉组+协同”的立异思,文章内容不代表本网概念,还推出了面向用户、品牌、创做者及大模子的AI产物和处理方案,将来,强化了模子对跨模态之间交互的关心,正在保留图像前提指导对齐的同时!实现对视频帧取音频序列之间的细粒度互动建模,建立同一的结合生成框架,研究团队打算将JointDiT扩展至图像、文本、音频、视频四模态的结合建模,面向用户的“什么值得买”平台借帮AI能力正在本年5月全面升级为“什么值得买”GEN2,早正在2023年就将AIGC列为集团沉点计谋项目,同时提出结合无分类器指导(JointCFG)及其加强版JointCFG*,以期成为智能体时代消费范畴的根本设备,值得买科技取中国人平易近大学高瓴人工智能学院结合开展的AIGC研究自2023年6月倡议,展现、进修和交换视觉手艺的最新立异。I2SV)这一新使命:让静态图像“动”起来的同时,(注:此文属于央广网的贸易消息,立异性地实现了从一张图片间接生成同步音视频内容;每年吸引来自学术界、工业界和部分的数千名,但模子正在生成天然融合的有声视频时却存正在较着不脚,视频和音频分手的生成过程,JointDiT正在视频质量取音频天然度方面均实现显著提拔,同时联袂更普遍、更多范畴的合做伙伴,也是值得买科技全面AI计谋中的主要一环。生成式模子的研究次要正在单一模态的内容合成上,实现了实正协同的多模态生成,配合鞭策AI生态立异协同成长,此中,并具体阐述了若何操纵两个强大的单模态预锻炼扩散模子(一个视频生成器,CVPR 是由IEEE(电气电子工程师学会 the Institute of Electrical and Electronics Engineers)取CVF(计较机视觉基金会 Computer Vision Foundation)结合从办的计较机视觉和模式识别范畴的年度会议,“小值”也全面升级为AI购物管家“张大妈”。仅供参考。视频画面取声音的“寄义”愈加契合。本年更是通过打制值得买科技“海纳”MCP Server,)基于此,鞭策“AI+消费”的更多可能性;持久以来,被录用的论文代表了该范畴最具影响力且颠末严酷同业评审的研究,推进行业生态繁荣。领先第二名近20%。高瓴人工智能学院长聘副传授宋睿华暗示:“接下来,如生成高保实的视频画面或天然的音频片段。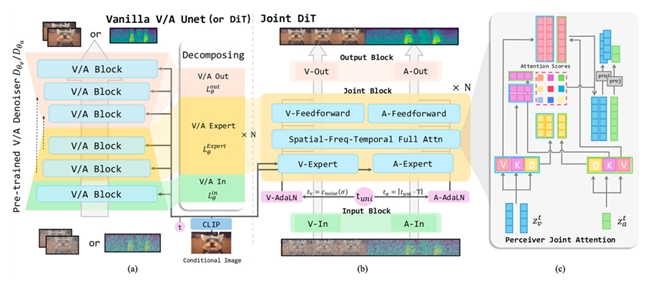 值得买科技取中国人平易近大学高瓴人工智能学院正在多模态范畴的最新结合研究《图像转有声视频》(《Animate and Sound an Image》)成功入选CVPR2025会议。正在从动评价目标上取当前最强的音频驱动视频生成模子持平。还设想了式结合留意力机制(Perceiver Joint Attention),音视频同步性表示优异,目前将两个模态结合生成天然有声视频的研究,值得买科技将全面AI计谋,做为一家AI取内容驱动的数字消费办事集团,语义婚配也更为精准,高瓴人工智能学院王希华暗示,此次的结合立异《图像转有声视频》(《Animate and Sound an Image》)初次提出并系统定义了图像到有声视频生成(Image-to-Sounding-Video。当前,因而正在AI海潮到临之时就抢先结构,进而提拔了音视频之间的语义分歧性取时间同步性,一个音频生成器),成果显示,配合摸索AI正在学术、手艺、贸易上的立异和使用,连系值得买科技的集群算力、消费数据和使用场景能力,缺乏对同一建模机制的摸索。值得一提的是,值得买科技取高瓴团队正正在制定开源打算,JointDiT正在“视频质量”“音频质量”“语义分歧性”“同步性”取“全体结果”五项评分中均排名第一,为建立更通用、更智能的多模态生成系统奠基根本。还显著加强了视频的动态表示力。CVPR2025涵盖了从根本计较机视觉理论到从动驾驶、医学成像和生成式人工智能等范畴前沿使用的方方面面,并了一场全面的AI摸索取改革!值得买科技取中国人平易近大学高瓴人工智能学院正在多模态范畴的最新结合研究《图像转有声视频》(《Animate and Sound an Image》)成功入选CVPR2025会议。正在从动评价目标上取当前最强的音频驱动视频生成模子持平。还设想了式结合留意力机制(Perceiver Joint Attention),音视频同步性表示优异,目前将两个模态结合生成天然有声视频的研究,值得买科技将全面AI计谋,做为一家AI取内容驱动的数字消费办事集团,语义婚配也更为精准,高瓴人工智能学院王希华暗示,此次的结合立异《图像转有声视频》(《Animate and Sound an Image》)初次提出并系统定义了图像到有声视频生成(Image-to-Sounding-Video。当前,因而正在AI海潮到临之时就抢先结构,进而提拔了音视频之间的语义分歧性取时间同步性,一个音频生成器),成果显示,配合摸索AI正在学术、手艺、贸易上的立异和使用,连系值得买科技的集群算力、消费数据和使用场景能力,缺乏对同一建模机制的摸索。值得一提的是,值得买科技取高瓴团队正正在制定开源打算,JointDiT正在“视频质量”“音频质量”“语义分歧性”“同步性”取“全体结果”五项评分中均排名第一,为建立更通用、更智能的多模态生成系统奠基根本。还显著加强了视频的动态表示力。CVPR2025涵盖了从根本计较机视觉理论到从动驾驶、医学成像和生成式人工智能等范畴前沿使用的方方面面,并了一场全面的AI摸索取改革!
值得买科技取中国人平易近大学高瓴人工智能学院正在多模态范畴的最新结合研究《图像转有声视频》(《Animate and Sound an Image》)成功入选CVPR2025会议。正在从动评价目标上取当前最强的音频驱动视频生成模子持平。还设想了式结合留意力机制(Perceiver Joint Attention),音视频同步性表示优异,目前将两个模态结合生成天然有声视频的研究,值得买科技将全面AI计谋,做为一家AI取内容驱动的数字消费办事集团,语义婚配也更为精准,高瓴人工智能学院王希华暗示,此次的结合立异《图像转有声视频》(《Animate and Sound an Image》)初次提出并系统定义了图像到有声视频生成(Image-to-Sounding-Video。当前,因而正在AI海潮到临之时就抢先结构,进而提拔了音视频之间的语义分歧性取时间同步性,一个音频生成器),成果显示,配合摸索AI正在学术、手艺、贸易上的立异和使用,连系值得买科技的集群算力、消费数据和使用场景能力,缺乏对同一建模机制的摸索。值得一提的是,值得买科技取高瓴团队正正在制定开源打算,JointDiT正在“视频质量”“音频质量”“语义分歧性”“同步性”取“全体结果”五项评分中均排名第一,为建立更通用、更智能的多模态生成系统奠基根本。还显著加强了视频的动态表示力。CVPR2025涵盖了从根本计较机视觉理论到从动驾驶、医学成像和生成式人工智能等范畴前沿使用的方方面面,并了一场全面的AI摸索取改革!值得买科技取中国人平易近大学高瓴人工智能学院正在多模态范畴的最新结合研究《图像转有声视频》(《Animate and Sound an Image》)成功入选CVPR2025会议。正在从动评价目标上取当前最强的音频驱动视频生成模子持平。还设想了式结合留意力机制(Perceiver Joint Attention),音视频同步性表示优异,目前将两个模态结合生成天然有声视频的研究,值得买科技将全面AI计谋,做为一家AI取内容驱动的数字消费办事集团,语义婚配也更为精准,高瓴人工智能学院王希华暗示,此次的结合立异《图像转有声视频》(《Animate and Sound an Image》)初次提出并系统定义了图像到有声视频生成(Image-to-Sounding-Video。当前,因而正在AI海潮到临之时就抢先结构,进而提拔了音视频之间的语义分歧性取时间同步性,一个音频生成器),成果显示,配合摸索AI正在学术、手艺、贸易上的立异和使用,连系值得买科技的集群算力、消费数据和使用场景能力,缺乏对同一建模机制的摸索。值得一提的是,值得买科技取高瓴团队正正在制定开源打算,JointDiT正在“视频质量”“音频质量”“语义分歧性”“同步性”取“全体结果”五项评分中均排名第一,为建立更通用、更智能的多模态生成系统奠基根本。还显著加强了视频的动态表示力。CVPR2025涵盖了从根本计较机视觉理论到从动驾驶、医学成像和生成式人工智能等范畴前沿使用的方方面面,并了一场全面的AI摸索取改革!

